Con lo sviluppo esponenziale dell'Intelligenza Artificiale Generativa, è diventato sempre più difficile distinguere i contenuti creati dalle macchine da quelli prodotti dagli esseri umani. Se 5 o 6 anni fa eravamo già preoccupati dal dilagare di fake news e video deepfake, oggi la situazione è ancora più grave. I social sono invasi da “AI slop”, mentre il web si riempie di applicazioni sviluppate interamente con l'IA, spesso prive di supervisione adeguata. È quindi diventato fondamentale sviluppare sistemi e tecnologie in grado di permettere a utenti e applicazioni di riconoscere se un contenuto – sia esso un video, un testo, un'immagine o una musica – è stato generato totalmente o parzialmente da una macchina. Ma è ancora possibile farlo? E quanto sono affidabili i sistemi che stanno nascendo per questo scopo? In questa puntata proviamo a rispondere a queste domande.
Nella sezione delle notizie parliamo di una nuova tecnica CRISPR contro i tumori, della class action contro Apple per le promesse non mantenute su Siri e Apple Intelligence e infine dell'avvio della produzione del camion elettrico di Tesla.


Brani
• Ecstasy by Rabbit Theft
• Falling For You by SouMix & Bromar
Salve a tutti, siete all'ascolto di INSiDER - Dentro la Tecnologia, un podcast di Digital People e io sono il vostro host, Davide Fasoli.
Oggi affronteremo uno dei temi più urgenti nell'era dell'Intelligenza Artificiale Generativa, come riconoscere se un contenuto è stato generato da una macchina o da un essere umano.
Analizzeremo le tecnologie di watermarking invisibile come SynthID e lo standard C2PA, i loro punti di forza e i loro limiti, per capire se siamo davvero in grado di distinguere il vero dal falso in un web sempre più saturo di contenuti artificiali.
Prima di passare alle notizie che più ci hanno colpito questa settimana, vi ricordo che potete seguirci su Instagram a @dentrolatecnologia, iscrivervi alla newsletter e ascoltare un nuovo episodio ogni sabato mattina, su Spotify, Apple Podcast, YouTube Music oppure direttamente sul nostro sito.
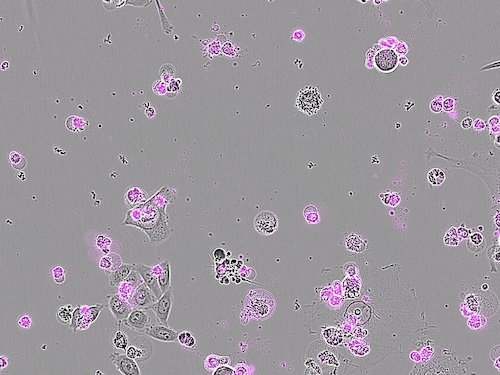
La tecnica CRISPR, di cui abbiamo parlato in una delle primissime puntate del podcast, è ormai diventata uno strumento fondamentale nella ricerca biomedica.
Grazie a una proteina, la Cas9, è infatti possibile modificare con precisione le catene di DNA delle cellule.
Recentemente, però, un gruppo di ricercatori guidato dalla University of Utah Health ha sviluppato una tecnica simile in cui, invece di modificare il DNA, questo viene distrutto completamente.
Alla base c'è un'altra proteina, la Cas12a2, che una volta riconosciuto il bersaglio, ad esempio una specifica sequenza di DNA, inizia a tagliare il materiale genetico fino a portare la cellula all'autodistruzione.
Lo scopo, dunque, non è quello di correggere, come nel caso delle tecniche CRISPR attuali, ma eliminare tutto ciò che incontra.
E le applicazioni sono molteplici.
Nello studio viene infatti dimostrato che dopo averla programmata per colpire una mutazione delle cellule che causano il tumore al polmone, questa tecnica ha avuto un'efficacia paragonabile a quella dei farmaci antitumorali, ma senza danneggiare le cellule sane circostanti.
Allo stesso modo, la proteina Cas12a2 si è dimostrata efficace nel distruggere le cellule infettate dal papillomavirus umano e, secondo i ricercatori, potrebbe essere facilmente adattata per colpire anche altri virus, come l'HIV.
Se questi risultati verranno confermati anche su organismi più complessi, dunque, la tecnica potrebbe offrire una nuova frontiera per terapie estremamente mirate contro infezioni virali e tumori, superando uno dei limiti più importanti dei trattamenti attuali, ovvero gli effetti collaterali sui tessuti sani.
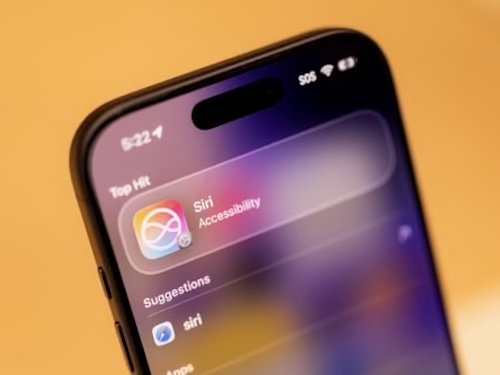
Apple pagherà 250 milioni di dollari per chiudere una class action negli Stati Uniti legata alle promesse fatte su Siri e sulle nuove funzioni di intelligenza artificiale di Apple Intelligence.
Secondo l'accusa, l'azienda avrebbe pubblicizzato una versione completamente rivoluzionaria dell'assistente vocale, capace di comprendere il contesto personale degli utenti, interagire con le app in modo avanzato e offrire risposte molto più intelligenti e personalizzate.
Una campagna che aveva creato grandi aspettative e aveva spinto molti consumatori ad acquistare iPhone 15 e iPhone 16, convinti di ricevere fin da subito queste novità.
In realtà, però, gran parte delle funzioni promesse non è mai arrivata nei tempi annunciati e alcune non sono ancora disponibili.
Per questo Apple è stata accusata di aver esagerato nelle pubblicità, vendendo un futuro che di fatto non si è mai concretizzato.
L'accordo riguarda gli utenti statunitensi che hanno acquistato i dispositivi tra il 2024 e il 2025 e prevede rimborsi fino a 95 dollari per ogni iPhone idoneo.
Apple non ha ammesso colpe, ma intanto continua a lavorare a una nuova versione di Siri basata sull'IA.
Tesla ha avviato la produzione del camion elettrico "Semi" presso lo stabilimento in Nevada, segnando il passaggio dalla fase sperimentale, iniziata circa dieci anni fa, a quella industriale, che punterà a garantire continuità, scalabilità e standardizzazione.
L'impianto è stato realizzato per riuscire a produrre fino a 50.000 unità all'anno, un livello che se raggiunto consentirebbe a Semi di conquistare una quota rilevante del mercato nordamericano dei truck pesanti di classe 8, storicamente dominato dalla trazione diesel.
Tuttavia, per l'anno in corso, le stime prevedono una produzione tra le 5.000 e le 15.000 unità, numeri che in realtà riflettono le normali dinamiche di avvio, per l'ottimizzazione dei cicli produttivi e la stabilità della catena di fornitura.
Come annunciato poco fa, il programma Semi è stato annunciato da Tesla nel 2017, con le prime consegne effettive avviate solo nel 2022, dopo ripetuti ritardi e in quantità molto contenute.
L'avvio della produzione in serie rappresenta invece il vero banco di prova per questo nuovo mezzo, soprattutto nel contesto di un segmento di mercato nel quale l'elettrico non ha molti precedenti, sia in termini di utilizzo, affidabilità e convenienza su ampia scala.
Se c'è una tecnologia che negli ultimi anni ha saputo imporsi fino a essere considerata una vera e propria rivoluzione, al pari di Internet o della rivoluzione industriale, quella è l'intelligenza artificiale generativa.
A differenza degli algoritmi di machine learning o deep learning, queste tipologie di intelligenze artificiali, che ormai abbiamo imparato a conoscere ed utilizzare, sono la forma più vicina a una "AGI" che l'uomo sia riuscito a sviluppare.
Per chiarire, una AGI, o intelligenza artificiale generale, è un'IA in grado di comprendere, apprendere e svolgere qualsiasi compito, anche intellettuale, finora attribuito all'essere umano.
Se pensiamo, quindi, che ormai applicazioni come ChatGPT, Claude o Gemini riescono non solo a capire ciò che scriviamo, ma anche a fornire risposte articolate, a usare in modo autonomo o quasi un computer e a generare immagini, video o musica, è chiaro quanto ormai ci stiamo avvicinando a quel tipo di intelligenza.
E il futuro che ci aspetta è tanto sorprendente quanto spaventoso.
Già oggi, infatti, è diventato quasi impossibile riconoscere una foto o un video generati da un'intelligenza artificiale.
E ancora più difficile è capire se un testo, magari un articolo di giornale o un paper scientifico, sia stato generato dall'IA o meno.
Ecco quindi che se 5 o 6 anni fa eravamo già preoccupati dal dilagare di fake news o video deepfake, oggi la situazione è ancora più grave e può sfuggire di mano da un momento all'altro.
I social sono ormai invasi da cosiddetti "AI slop", ossia video ironici o sensazionalistici generati con modelli come Sora o Gemini che stanno sempre più oscurando contenuti umani, spesso più interessanti, informativi e capaci di portare del reale valore aggiunto agli utenti e alle piattaforme.
E la stessa cosa vale anche per i servizi digitali, con un web sempre più saturo di applicazioni improvvisate e sviluppate interamente con l'IA, prive di supervisione adeguata e con evidenti problemi di qualità, sicurezza e gestione delle informazioni.
È dunque chiaro quanto sia diventato di fondamentale importanza affiancare allo sviluppo dell'IA generativa lo sviluppo di sistemi e tecnologie in grado di permettere ad utenti e applicazioni di riconoscere se un contenuto, sia esso un video, un
testo, un'immagine o una musica, è stato generato totalmente o parzialmente da una macchina o da un essere umano.
Ed è proprio questo il tema su cui ci focalizzeremo oggi.
Sistemi del genere stanno infatti già venendo sviluppati e in questa puntata andremo a riconoscerli, analizzarne il funzionamento tecnico e soprattutto capire se sono veramente affidabili e pronti per il prossimo futuro.
Partiamo dai metodi più intuitivi, purtroppo sempre più difficili da attuare, ma che permettono di riconoscere a colpo d'occhio soprattutto ai più esperti, i contenuti artificiali.
Per il testo ci sono infatti alcune caratteristiche spesso comuni a tutti i modelli linguistici.
Questi modelli producono sequenze di parole in modo probabilistico, per cui il risultato tende a essere statisticamente prevedibile, con frasi che hanno una struttura regolare e scelte lessicali tendenzialmente ovvie.
Mancano poi quelle imprecisioni o quelle piccole sviste che rendono i testi più, tra virgolette, "umani".
Anche la lunghezza delle frasi è più uniforme per i modelli linguistici, che tendono ad alternare frasi più lunghe a frasi più brevi, in modo più regolare rispetto a quanto farebbe un essere umano.
Torna poi il discorso che abbiamo approfondito nella puntata "Abbiamo bisogno di un'IA Made in Italy?".
Con modelli addestrati prevalentemente su contenuti in lingua inglese, le altre lingue tendono a ereditare strutture, o modi di dire tipici delle lingue anglosassoni, o ad italianizzare, nel nostro caso, alcuni termini tecnici.
Per le immagini generate da sistemi come Midjourney, Nano Banana o Stable Diffusion, la situazione è un po' più semplice, almeno per ora.
Questi modelli, per quanto migliorati enormemente negli ultimi anni, fanno ancora fatica con certi dettagli, ed è spesso possibile notare sfocature nei bordi degli oggetti, sfondi con texture incoerenti, occhi che non riflettono la luce in modo naturale o testi illeggibili integrati nell'immagine.
Per i video, infine, i segnali sono, fortunatamente per ora, più evidenti, con bocche non perfettamente sincronizzate con l'audio o espressioni, luci e movimenti innaturali.
Se l'essere umano è quindi in grado di riconoscere contenuti generati artificialmente, è logico chiedersi se possano esistere anche sistemi automatici in grado di farlo.
La risposta è sì, e online si possono trovare servizi e modelli, anch'essi di intelligenza artificiale, che hanno proprio l'obiettivo di classificare testi, immagini o video.
Uno tra i più noti è GPTZero, uno strumento sviluppato nel 2022 che - teoricamente - è in grado di riconoscere un testo generato da modelli come GPT.
La realtà, però, è sfortunatamente ben diversa.
Questi strumenti hanno infatti una accuratezza estremamente bassa, circa del 40% secondo studi indipendenti.
Ciò significa che è molto facile o ingannare il modello, banalmente riformulando alcune frasi, o incappare in falsi positivi, ossia in contenuti che vengono erroneamente classificati come generati dall'IA, seppur scritti da esseri umani.
Questo può accadere, ad esempio, con gli articoli scientifici, dove ricercatori non madrelingua tendono a utilizzare una sintassi più semplice e prevedibile, che si avvicina a quella delle IA generative.
L'inaffidabilità di questi strumenti, quindi, ci porta ad approfondire una terza tecnica, ossia il "watermarking invisibile".
Se qualcuno ha provato a generare un video con Sora di OpenAI o un'immagine con NanoBanana di Google, ha sicuramente notato che viene applicato il logo della piattaforma solitamente in un angolo dell'immagine o del video.
Ecco, quello è un esempio di watermarking visibile, che però funziona fino a un certo punto.
Basta ritagliare l'immagine o usare un'altra IA per coprire il logo, per rimuovere o nascondere la firma.
Serve quindi qualcosa di molto più sofisticato.
Ed è qui che entrano in gioco due tecnologie principali che si stanno affermando come riferimenti nel mercato dell'IA generativa.
SynthID e lo standard C2PA.
Partiamo da SynthID.
Questo progetto è forse il più avanzato attualmente disponibile ed è stato sviluppato da Google DeepMind con l'obiettivo di applicare un watermark invisibile e non rimovibile a tutti i contenuti, dal testo alle immagini, dal video all'audio, generati con i modelli di Google.
Per quanto riguarda immagini e video, SynthID altera in modo impercettibile all'occhio umano il colore dei pixel, creando una vera e propria firma unica e visibile solamente ad un algoritmo.
Per quanto riguarda l'audio, invece, è l'onda sonora ad essere alterata, andando solitamente a toccare quelle frequenze non udibili all'orecchio umano.
Per il testo il meccanismo è leggermente più complesso, e per certi versi ancora più interessante.
Come abbiamo già anticipato, tutti i modelli di IA generativa che producono contenuti testuali si basano sulla statistica per scegliere di volta in volta quale è la parola, o per essere precisi il token, che ha la maggior probabilità di legarsi alle parole precedenti formando frasi di senso compiuto.
SynthID interviene proprio in questa fase, alterando quella probabilità attraverso una funzione chiamata "g-function".
Il risultato è una frase che rimane perfettamente sensata e corretta, ma che nasconde in realtà una firma illeggibile, in quanto solo un modello di IA che ha usato SynthID avrebbe potuto scegliere quella precisa sequenza di parole.
Il codice di SynthID per la generazione di testo, tra l'altro, è open source, e disponibile pubblicamente sul sito Hugging Face, quindi accessibile a qualsiasi sviluppatore e non solo a Google.
Ma veniamo ora ad analizzare i punti di forza e soprattutto i limiti di questa tecnologia.
Il primo vantaggio è che SynthID non può essere rimosso facilmente ritagliando un'immagine, alterando i colori, o facendo uno screenshot.
La firma è infatti applicata a livello di pixel e viene mantenuta anche in presenza di trasformazioni o alterazioni dell'immagine o del video.
Addirittura, grazie a questo watermark, è possibile identificare se solo una parte del contenuto è stata generata artificialmente o meno, garantendo una granularità maggiore e più sofisticata rispetto ad altri sistemi.
Per quanto riguarda i limiti, è di poche settimane fa la notizia per cui uno sviluppatore è riuscito proprio a violare il meccanismo dietro il watermarking invisibile e creare uno strumento in grado di rimuoverlo completamente alterando in modo chirurgico pixel per pixel.
Per il testo, invece, la situazione è al momento più solida e attualmente l'unico modo realmente efficace per aggirare il watermark è quello di riscrivere o alterare in modo molto significativo il testo prodotto da Gemini.
Ma a quel punto la questione diventa più filosofica che tecnica.
Fino a che punto un testo profondamente riscritto da un essere umano può ancora essere considerato artificiale?
Ovviamente a maggio 2025 Google ha anche rilasciato un tool chiamato "SynthID Detector" proprio per identificare il watermark di SynthID e permettere a chiunque di verificare se un testo, un'immagine, un video o un audio sono stati generati da modelli della famiglia Gemini.
Alla data del lancio, oltre 10 miliardi di contenuti erano già stati marcati con SynthID attraverso i prodotti Google.
Il limite principale, però, è che SynthID non è uno standard universale, ma copre solo i contenuti prodotti da Google, lasciando fuori la grande maggioranza dei contenuti generati da altri sistemi.
Ciò che invece hanno adottato aziende come Microsoft, OpenAI o Adobe è lo standard C2PA, acronimo di Coalition for Content Provenance and Authenticity.
Prima di approfondirne il funzionamento è bene precisare che queste aziende applicano lo standard solamente a contenuti multimediali come immagini o video.
Per il testo, né OpenAI né Anthropic hanno ad oggi implementato sistemi di watermarking equivalenti a quello di Google, anche se il tema è presente nelle rispettive roadmap di sviluppo.
Tornando a noi, lo standard C2PA definisce quello che viene chiamato "Content Credential", ossia una sorta di carta d'identità, crittografata e certificata, che permette di risalire non solo all'autore del contenuto, compresa un'IA, ma anche di
tracciare le modifiche che sono state effettuate, da chi, e con quali strumenti, a patto che il software utilizzato aderisca allo standard come fa ad esempio Adobe Photoshop.
Trattandosi di uno standard aperto, è normale che la sua adozione sia pressoché globale tra le principali aziende tecnologiche, da OpenAI ad Adobe ma anche da Google o TikTok, che implementano nelle rispettive piattaforme la lettura della Content Credential per fornire informazioni all'utente.
È però fondamentale chiarire e sottolineare il limite più importante di questo approccio, ossia che queste informazioni, seppur verificate e crittografate, vengono inserite attraverso i metadati.
Questo significa che è sufficiente rimuovere quei metadati o effettuare uno screenshot per rendere questo sistema completamente inutilizzabile, senza considerare che le stesse piattaforme di messaggistica come WhatsApp spesso rimuovono automaticamente i metadati dai contenuti inviati per motivi di privacy.
Arrivati alla conclusione di questa puntata, quindi, quello che emerge è un quadro complesso, in cui non esiste una soluzione unica e definitiva, ma diversi sistemi frammentati, ciascuno con i propri punti di forza e, soprattutto, con i propri limiti.
I rilevatori automatici basati su modelli di Machine Learning possono essere utili, ma hanno tassi di errore che li rendono inadatti a supportare decisioni definitive.
Il watermarking invisibile come SynthID è tecnologicamente sofisticato e promettente, ma copre ancora solo una parte dei contenuti generati dall'IA e richiederebbe l'adesione di tutti i produttori per diventare davvero rilevante.
Le Content Credential del C2PA, infine, rappresentano attualmente l'approccio più scalabile e interoperabile, ma sono necessari sistemi di sicurezza aggiuntivi per rendere più difficile la rimozione dei metadati.
Con lo sviluppo dell'IA generativa sempre più accelerato, e modelli in grado di generare testi o immagini ormai quasi indistinguibili dalla realtà, come dimostrano i recenti rilasci di modelli come Seedance 2.0, Nano Banana o GPT Image 2, vale
quindi la pena chiedersi quanto sistemi di watermarking e di credenziali possano diventare rilevanti e necessari nei prossimi anni.
Se da una parte regolamenti come l'AI Act hanno infatti introdotto obblighi specifici di trasparenza, riguardo questi contenuti, dall'altra parte il problema della veridicità delle informazioni rimane irrisolto.
Una firma digitale ci dice da dove viene un contenuto, ma non se è vero.
E come ben sappiamo, anche la realtà può essere facilmente alterata, banalmente decontestualizzando fotografie o affermazioni.
Ecco quindi che non solo è assolutamente fondamentale investire nelle tecnologie di watermarking e rilevamento, ma serve anche un profondo cambio culturale e un'alfabetizzazione di tutti noi che ci insegni a chiederci, indipendentemente dalla fonte
o dal creatore di un contenuto, se ciò che stiamo guardando, leggendo o ascoltando corrisponda alla realtà oggettiva dei fatti.
E così si conclude questa puntata di INSiDER - Dentro la Tecnologia, io ringrazio come sempre la redazione e in special modo Matteo Gallo e Luca Martinelli che ogni sabato mattina ci permettono di pubblicare un nuovo episodio.
Per qualsiasi tipo di domanda o suggerimento scriveteci a redazione@dentrolatecnologia.it, seguiteci su Instagram a @dentrolatecnologia dove durante la settimana pubblichiamo notizie e approfondimenti.
In qualsiasi caso nella descrizione della puntata troverete tutti i nostri social.
Se trovate interessante il podcast condividetelo che per noi è un ottimo modo per crescere e non dimenticate di farci pubblicità.
Noi ci sentiamo la settimana prossima.