
Nel 2001 nasceva un'enciclopedia online che in pochi anni avrebbe cambiato per sempre il modo in cui accediamo alla conoscenza. Oggi, a 25 anni di distanza, Wikipedia è diventata una delle piattaforme più consultate al mondo: gratuita, collaborativa, in continua evoluzione. Dietro a quelle pagine che milioni di persone aprono ogni giorno, però, non c'è solo un sito web, ma un ecosistema complesso fatto di tecnologia, infrastrutture digitali e una enorme community. Per capire come funziona tutto questo, quali sono le sfide tecnologiche e culturali che affronta ogni giorno Wikimedia e il suo ruolo nel contrastare la disinformazione in un'epoca dominata dall'intelligenza artificiale, abbiamo invitato Ferdinando Traversa, Presidente di Wikimedia Italia.
Nella sezione delle notizie parliamo dell'app europea per la verifica dell'età e dell'approvazione olandese per il sistema Full Self-Driving Supervised di Tesla, che apre le porte a una possibile adozione in Europa.


Brani
• Ecstasy by Rabbit Theft
• Halo (I'll Be There) by Poylow, Misfit, MAD SNAX
Migliaia di persone scrivono su Wikipedia e modificano i progetti a fin di bene, forse quasi altrettante, provano o per gioco o per test o con intenzioni malevole per esempio quella di fare dello spam o quella di fare della diffamazione o di inserire contenuti falsi, a minare l'affidabilità dei contenuti presenti nel progetto.
E quindi riceviamo anche tantissime modifiche, che siano il semplice inserimento di lettere a caso - per dire, no, la più innocente - all'inserimento di informazioni false senza fonti inventate che la comunità dei volontari ogni giorno si impegna a contrastare monitorando proprio quelle che sono le ultime modifiche.
Salve a tutti, siete all'ascolto di INSiDER - Dentro la Tecnologia, un podcast di Digital People e io sono il vostro host, Davide Fasoli.
Oggi parleremo con Wikimedia Italia di come funziona l'ecosistema dietro Wikipedia, uno dei siti più consultati al mondo, e degli altri progetti come Wikidata e OpenStreetMap.
Scopriremo le sfide tecnologiche e culturali nel mantenere gratuiti questi strumenti e come garantire l'affidabilità delle informazioni in un modello dove tutti possono contribuire.
Prima di passare alle notizie che più ci hanno colpito questa settimana, vi ricordo che potete seguirci su Instagram a @dentrolatecnologia, iscrivervi alla newsletter e ascoltare un nuovo episodio ogni sabato mattina, su Spotify, Apple Podcast, YouTube Music oppure direttamente sul nostro sito.
Nell'ultimo periodo diversi governi, compresa l'Unione Europa con il Digital Services Act, stanno imponendo dei limiti d'età per gli utenti online, con lo scopo principale di vietare ai minori l'accesso a social network, siti pornografici o altre app o siti considerati pericolosi.
Per adeguarsi alle normative, quindi, è necessario che i siti coinvolti implementino sui loro portali la verifica dell'età dell'utente.
Proprio per questo la presidente della Commissione Europea ha annunciato questo giovedì l'app europea dedicata proprio alla verifica dell'età.
L'app in questione è stata sviluppata nel corso degli ultimi mesi e ha la caratteristica di essere open source e con una particolare attenzione alla privacy di chi la utilizza.
Inoltre, l'app in questione è una "white-label", ciò significa che i vari stati europei possono utilizzarne il codice per integrarla nei loro portafogli digitali.
Un esempio italiano è l'App IO, su cui probabilmente verrà integrata.
Il funzionamento è abbastanza semplice: l'app chiede di caricare un documento di identità o di dimostrare la propria età attraverso altri sistemi di identificazione.
Dopodiché, basterà inquadrare un QR code sul sito a cui si vuole accedere per confermare che l'utente ha superato una certa età - ad esempio i 14 o 18 anni - e sbloccare l'accesso.
Per Von Der Leyen, a questo punto, i portali non hanno più scuse per non integrare dei sistemi adeguati di verifica dell'età, avendo già a disposizione uno strumento funzionante e in regola con tutte le normative europee.
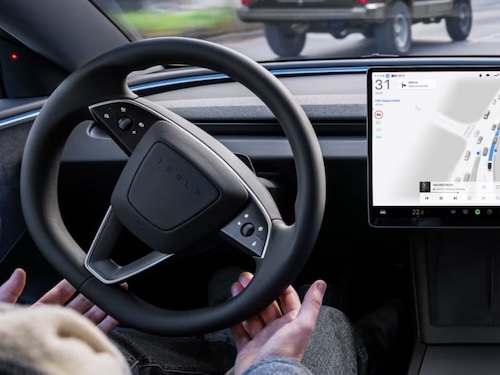
Tesla ha ottenuto l'approvazione ufficiale del proprio sistema "Full Self-Driving Supervised" da parte dell'autorità olandese, aprendo la strada a una prima diffusione della tecnologia nel mercato europeo.
In questo caso il sistema consente alla vettura di gestire autonomamente numerose funzioni di guida, pur richiedendo la costante supervisione del conducente, che deve mantenersi vigile e pronto a intervenire in qualsiasi momento.
La dicitura "Supervised" è stata infatti introdotta anche in risposta alle pressioni regolamentari, con l'obiettivo di distinguere chiaramente questa modalità rispetto alla guida autonoma completa.
In questo caso il via libera dall'autorità olandese potrebbe posizionarsi come riferimento normativo per gli altri Stati membri dell'Unione Europea, aprendo la pista a una possibile adozione progressiva da parte dei singoli Paesi.
Per conseguire l'omologazione, Tesla ha condotto un'estesa campagna di test in Europa, percorrendo circa 1,6 milioni di chilometri con il sistema attivo e coinvolgendo circa 13.000 clienti come passeggeri in diversi scenari in ambienti controllati.
Nel 2001 nasceva un'enciclopedia online che in pochi anni avrebbe cambiato per sempre il modo in cui accediamo alla conoscenza.
Oggi, a 25 anni di distanza, Wikipedia è diventata una delle piattaforme più consultate al mondo, gratuita, collaborativa, in continua evoluzione.
Dietro a quelle pagine che milioni di persone aprono ogni giorno, però, non c'è solo un sito web, ma un ecosistema complesso fatto di tecnologia, infrastrutture digitali e un'enorme community.
E per capire come funziona tutto questo, quali sono le sfide tecnologiche e culturali che affronta ogni giorno Wikimedia, la realtà dietro Wikipedia, è con noi Ferdinando Traversa, Presidente di Wikimedia Italia.
Benvenuto Ferdinando.
Ciao a tutti.
Che cos'è quindi Wikimedia, che legame ha con Wikipedia, che sentiamo più spesso nominare, come siete nati e che progetti avete sviluppato nel corso di questi anni?
Perché appunto oltre a Wikipedia ci sono... penso ad esempio ad altri progetti come MediaWiki, Wikimedia Commons, Wikidata, OpenStreetMap.
Allora, la Wikimedia Foundation è nata qualche anno dopo Wikipedia, che è un progetto appunto come dicevamo nato nel 2001, a un certo punto ci si è resi conto che questo progetto che stava crescendo in termini di utenti e anche in termini di
necessità di risorse tecnologiche per essere fruibile da così tante persone, non poteva più essere gestito dal solo fondatore appunto Jimmy Wales, che peraltro l'aveva avviato tramite la società che aveva ai tempi, e quindi l'idea fu proprio
quella di rimettere il controllo di questo progetto nelle mani di un ente con una governance anche più condivisa e così nacque la Wikimedia Foundation e poi nel tempo è nata non solo tutta una serie di progetti "fratelli", tra cui appunto c'è
Wikimedia Commons, c'è Wikidata, c'è MediaWiki, ma anche una serie di organizzazioni, di associazioni a livello territoriale, nazionale, che si chiamano "capitoli" appunto, sono affiliati della Wikimedia Foundation, tra cui appunto Wikimedia
Italia, che è nata nel 2005, ma nello stesso periodo più o meno sono anche nati gli omologhi svizzeri, francese, inglese e così via.
E quindi adesso in tutta Europa e in tutto il mondo - chiaramente a seconda di dove è più o meno attiva e presente la comunità dei progetti Wikimedia - c'è un capitolo della Wikimedia Foundation che svolge delle attività a livello territoriale.
Per quanto riguarda i progetti fratelli, sicuramente MediaWiki, nato quasi subito, è il motore tecnico che sta dietro Wikipedia, ma non solo, c'è un software che adesso è utilizzato da tantissime wiki, perché è molto facile da installare, è
scritto appunto in PHP, si collega a un database e chiunque può crearsi la sua wiki e quindi non solo i progetti Wikimedia utilizzano MediaWiki, ma anche la quasi totalità magari delle wiki tematiche che con noi non c'entrano niente, però potete tranquillamente consultare su web.
Che ne so... se siete appassionati di un determinato film, sicuramente c'è la wiki specifica dedicata a quel film, ai suoi personaggi, a una serie tv, ci sono tante comunità online e MediaWiki è appunto il motore dietro queste comunità.
Wikidata, che è il progetto più giovane, ed è una grande collezione di dati strutturati, quindi sono questi dati su tutto ciò che ci circonda, può essere oggetti, persone, che vengono rappresentati in modo da essere leggibili da parte di un
sistema automatico e questa cosa è molto potente, pensate a tutte le schede... navigando, quasi tutti avranno fatto caso che Google ogni tanto ci propone una scheda con delle informazioni riassuntive sui soggetti, se io cerco "Sergio Mattarella"
per dire, c'è una scheda con tutte le informazioni, un breve estratto di Wikipedia e tutti gli altri dati presi da Wikidata, perché è proprio tramite questi oggetti, questi dati presenti su Wikidata, che possono essere persone, possono essere
pianeti, possono essere città, su Wikidata ci sono centinaia di milioni di item, rappresentano queste informazioni che poi sono facilmente leggibili.
C'è poi Wikimedia Commons, che è un grande archivio fotografico multimediale, ci sono più di 100 milioni di video, file audio, immagini, tutte fruibili, con licenza libera, che è la caratteristica fondamentale dei progetti Wikimedia, quindi
pensate a un grande archivio fotografico con moltissime immagini di monumenti, di luoghi, di oggetti, tutte utilizzabili per produrre qualsiasi tipo di contenuto.
Ci sono altri progetti ancora come Wikisource, che è una biblioteca digitale, e poi ce ne sono ancora altri, magari non mi soffermo su tutti.
OpenStreetMap, che vi menzionavi prima, è interessante perché non è un progetto della Wikimedia Foundation, ma è un progetto che noi come Wikimedia Italia supportiamo, perché siamo anche capitolo dell'OpenStreetMap Foundation.
É un progetto che utilizziamo anche noi per esempio su Wikipedia per rappresentare le mappe, perché è un grande database geografico, una Wikipedia delle mappe, è un database geografico collaborativo dove ci si trova insieme non per scrivere tanto
le voci nella enciclopedia, ma per mappare un po' tutto quello che è invisibile, e poi vengono generate anche le effettive mappe che possiamo utilizzare sui siti web o consultare.
Quindi quello che fate ha avuto un grandissimo impatto in questi 25 anni sulla vita di tutti noi.
Però quali sono le difficoltà principali nel mantenere attive e online tutte queste funzioni, tutti questi progetti e farlo, ovviamente, come sappiamo gratuitamente, però immagino che sia necessaria un'infrastruttura tecnologica, server, database da gestire che è molto rilevante, ecco.
Sicuramente c'è un problema infrastrutturale e quindi anche di costo dell'infrastruttura.
Generalmente la Wikimedia Foundation spende una parte consistente del suo budget solo proprio fisicamente per mantenere i server, pagare gli sviluppatori che continuano lo sviluppo di MediaWiki - per quanto sia uno sforzo anche comunitario con
sviluppatori che lavorano appunto a titolo volontario perché è open source il software - però c'è anche tutta una parte di sviluppatori di infrastruttura, di gestione dell'infrastruttura che è molto costosa e sta diventando sempre più costosa
non solo per gli accessi umani che comunque sono un numero molto consistente, ma abbiamo avuto delle difficoltà recentemente anche a gestire gli accessi da sistemi automatici, cioè tutti i sistemi di intelligenza artificiale, tutti i bot che
vengono a "pescare" informazioni da Wikipedia, dai progetti Wikimedia, specie quando poi richiedono per esempio dei file multimediali da Wikimedia Commons, diventa molto pesante gestire questi accessi, abbiamo avuto recenti aumenti proprio di carico sull'infrastruttura.
E questa è una difficoltà ed è un costo molto importante.
E poi c'è la difficoltà umana chiaramente nel senso che migliaia di persone scrivono su Wikipedia e modificano i progetti a fin di bene, forse quasi altrettante, provano o per gioco o per test o con intenzione malevola per esempio quella di fare
dello spam o quella di fare della diffamazione o di inserire contenuti falsi a minare l'affidabilità dei contenuti presenti nel progetto e quindi riceviamo anche tantissime modifiche che siano il semplice inserimento di lettere a caso, per dire, la
più innocente, all'inserimento di informazioni false senza fonti inventate che la comunità dei volontari ogni giorno si impegna a contrastare monitorando proprio quelle che sono le ultime modifiche e poi un altro aspetto della difficoltà umana
chiaramente è che siamo sempre in cerca non solo... come vedrete c'è il solito banner delle donazioni a cui siamo tutti abituati e quello purtroppo ci tocca farlo perché sono fondi fondamentali per il mantenimento dell'infrastruttura e dei vari
servizi, ma soprattutto c'è la necessità di avere sempre un nuovo afflusso di contributori di editor di persone che si impegnino con la nuova volontà a migliorare i contenuti.
Sì che poi forse molti di noi accedono alle informazioni presenti su Wikipedia senza sapere però che le informazioni stesse sono scritte, modificate e aggiornate da persone comuni, ecco, quindi chiunque può modificare e la difficoltà sta proprio
nel contrastare interventi "malevoli" da parte oggi anche di bot o comunque chi fa scraping di informazioni per addestrare modelli di intelligenza artificiale, però penso che anche la stessa intelligenza artificiale può essere utilizzata per fare
dei tra virgolette "attacchi" di modifica, quindi l'IA viene utilizzata - l'IA generativa in particolare - per modificare in massa grandi quantità di contenuti.
Oggi rimane sostenibile questo modello definito "crowd-sourced", quindi dove tutti contribuiscono non solo a creare, a scrivere contenuti, ma anche a verificare che le modifiche fatte da altri siano corrette, veritiere, anche appunto in un contesto
in cui dall'altra parte possono esserci strumenti molto sofisticati e capaci in massa di fare grandi quantità di modifiche?
E poi come si fa a garantire, al netto di questa premessa, che il contributo fatto da una persona, da un membro della community, sia affidabile, trasparente e il più oggettivo possibile come deve essere.
Allora, quando questo modello è partito per Wikipedia... perché chiaramente esisteva già in altri contesti, ma quando Wikipedia è partita con questo modello è stata una grande scommessa.
25 anni fa, festeggiamo quest'anno i 25 anni, Jimmy Wales ha detto: "vediamo cosa succede se apriamo l'enciclopedia a tutti".
E per ora ha funzionato, nel senso che negli ultimi 25 anni si è riusciti a costruire, nonostante molti detrattori all'inizio, adesso quasi ci sembrerebbe assurdo, però nei primi anni di Wikipedia, chiunque diceva dagli insegnanti ai giornalisti, cos'è questa Wikipedia, non è affidabile.
La comunità è riuscita negli anni, la saggezza della folla diciamo, un po' questo modello molto aperto, è riuscita a costruire un prodotto molto valido, una fonte di conoscenza comunque affidabile, proprio perché si basa sulle fonti attendibili, le riporta e gli utenti ci tengono.
Chiaramente questo modello, particolarmente adesso, è di fronte a tante sfide.
La prima, come dicevi tu, quella dell'intelligenza artificiale generativa, che da un lato potenzia l'attività di chi vuole danneggiare il progetto, perché se voglio creare mille voci di Wikipedia in un solo colpo non ci metto più niente, mentre
prima dovevo scrivere mille voci false, adesso chiedo l'IA e mi generano mille voci false con tanto di fonti false, anch'esse, però ci sono.
Noi abbiamo delle linee guida per riconoscere quali possono essere i segnali dell'utilizzo di intelligenza artificiale, però chiaramente con l'evoluzione di questi sistemi stanno diventando molto meno riconoscibili.
D'altro canto, anche noi adesso utilizziamo l'intelligenza artificiale, da molto prima di ChatGPT e quant'altro, modelli di machine learning, niente di generativo, ma li utilizziamo per valutare il potenziale delle ultime modifiche, e quindi se
vediamo che una delle ultime modifiche è a "rischio vandalismo", come lo chiamiamo noi, ci viene evidenziato in rosso da questo modello che abbiamo, ed è più facile da individuare per chi poi va a fare il controllo manuale.
Alcune edizioni di Wikipedia in altre lingue, tipo spagnolo sicuramente, e inglese, si sono spinte oltre - questa è una cosa che si sta valutando anche in italiano - e c'è proprio un bot che annulla in automatico le ultime modifiche che hanno una
soglia di probabilità di essere dannose oltre un tot e poi eventualmente viene rivisto da un umano se in realtà era una modifica valida.
E così sicuramente si può contrastare più facilmente un afflusso di spam che per forza di cose, oltre a tutta un'altra serie di filtri e di strumenti automatici, tenderà a diventare sempre più ampio proprio perché diventerà molto più semplice.
E dall'altro lato, proprio perché appunto sta cambiando il modo di fruire la rete con l'intelligenza artificiale e sta cambiando anche il mondo di contribuire alle piattaforme online, cioè quest'idea del volontariato online assume forme diverse nel
tempo e non è più l'idea di volontariato online che c'era 25 anni fa, cioè adesso l'utente che... saranno molto meno le persone che dicono "sì dai andiamo a rispondere alle domande su Stack Overflow" per dire.
E quindi proprio perché sta cambiando un po' il modo in cui siamo abituati ad interagire con la rete, potremmo anche risentirne noi come Wikipedia, nel senso che a meno persone verrà in mente di dire "ma sì dai, andiamo ad aggiornare una voce di
Wikipedia" e questo può essere chiaramente un rischio del modello, quindi sicuramente è un modello che ha funzionato, sta funzionando e funziona, però chiaramente solo nella misura in cui c'è un afflusso di persone che partecipano.
Questa sarà la grande sfida anche per Wikipedia, come garantire la sostenibilità a lungo termine e anche il coinvolgimento, per esempio, dei giovani che sono abituati a tutto un altro tipo di piattaforme per la consultazione della conoscenza, vedi
YouTube, video, podcast, strumenti assolutamente diversi dalla lettura della pagina dell'enciclopedia.
Certo, poi secondo me c'è anche da dire che un grande elemento di forza di Wikipedia, rispetto anche a un sito tradizionale, è che oggi si tende a utilizzare molto anche per fare delle ricerche l'IA generativa, i chatbot, perché ormai i siti web
tradizionali, dove sono conservate le informazioni, sono pieni di pubblicità, che arrivi a un punto nel quale per recuperare l'informazione devi cliccare, devi chiudere una quantità innumerevole di pop-up.
Questo invece su Wikipedia non avviene, l'interfaccia è molto semplice e pulita, so dov'è l'informazione, è un'interfaccia familiare perché so che tutte le voci hanno la stessa interfaccia e quindi secondo me questo è un altro punto di forza.
Poi, giusto per non darlo per scontato, ci racconti come avviene il processo di review di una voce?
Cioè, una persona che fa parte della community può modificare.
La modifica viene subito approvata, ha bisogno di una revisione?
Allora, il bello è anche questo, chiunque può modificare anche senza essere registrato, la modifica è immediatamente visibile ma c'è una pagina delle ultime modifiche che viene monitorata con costanza da parte della comunità, i membri della
comunità che fanno questa attività che poi è aperta a tutti e si chiamano "Patroller", però chiunque, anche un nuovo arrivato potrebbe andare e consultare la pagina delle ultime modifiche e chi nota una modifica dannosa la può annullare e viene immediatamente riportata alla versione precedente.
Se l'utente è nuovo c'è anche un piccolo punto esclamativo rosso che appare accanto alla modifica così è più visibile, fin quando non viene segnata come verificata da parte di un altro utente più esperto.
Nel caso di modifiche reiterate da parte di un utente o su una specifica pagina - penso a pagine molto in vista - la modifica può essere inibita sia al singolo utente, quindi può essere bloccato l'utente, da un amministratore, che sono utenti che
hanno delle funzioni più avanzate, attribuite sempre dalla comunità con votazione, oppure può essere bloccata la modifica su una determinata pagina, per esempio in caso di pagine su temi molto caldi.
Ok e realizzate a proposito di questa community... come si fa a promuovere la conoscenza?
Cioè organizzate anche degli eventi dedicati appunto a questa community?
Come Wikimedia Italia il nostro impegno "offline", sul territorio, è proprio questo, cioè portiamo avanti sicuramente tanti eventi di divulgazione aperti al pubblico, con le istituzioni culturali, magari perché collaboriamo molto anche con le
istituzioni culturali per ottenere materiale di qualità da utilizzare poi sui progetti e per esempio organizziamo degli eventi che si chiamano "edit-a-thon" in cui ci vediamo in un luogo che può essere una biblioteca, ma può essere anche un
qualsiasi altro luogo per modificare, migliorare, aggiornare le voci relative a un determinato argomento che si sceglie per l'evento o stessa cosa si fa per esempio su OpenStreetMap, ma si chiama "Mapathon" quindi ci si vede per mappare una determinata area.
Abbiamo anche progetti con le scuole e con l'università per coinvolgere proprio gli studenti nell'approcciarsi per la prima volta a questo mondo e imparare a inserire informazioni corredate da relative fonti e quant'altro.
Abbiamo anche dei raduni, conferenze per la comunità insomma a livello nazionale, a livello internazionale dove ci si incontra per esempio per discutere di quelli che sono i principali problemi e le principali tematiche importanti per i progetti.
Ok poi un altro aspetto molto interessante sempre in parte legato alla community e ai contenuti è che se qualcuno magari si è imbattuto in una voce di Wikipedia in italiano si è reso conto che poi cambiando la lingua la voce in inglese o in un'altra lingua è molto più approfondita magari a volte poi può succedere il contrario.
E quindi si può fare qualcosa per evitare o comunque aggirare questo problema e quindi creare delle... non dico un'unica voce, perché ovviamente poi ci sono delle sfumature tra una versione in una lingua o nell'altra, ma per creare un contenuto che appunto sia accessibile a chiunque?
Quindi io che parlo italiano posso accedere anche alle informazioni scritte in inglese o in una lingua che non conosco.
Allora, questo è un po' anche un effetto voluto, nel senso che ogni edizione di Wikipedia chiaramente è a sé, fa la sua politica editoriale, capita spesso, come dici, che molte voci su temi più di interesse internazionale siano molto più
sviluppate in inglese, dove in inglese c'è una comunità chiaramente enorme, una scala di numero di voci diverse, 6.5 milioni voci, contro in italiano ne abbiamo quasi 2 milioni, viceversa chiaramente se si va su un tema più relativo all'Italia -
per quanto Wikipedia abbia assolutamente un approccio internazionale ai fatti, qui non è chiaramente Wikipedia Italia, è Wikipedia in italiano proprio per questo - però spesso ovviamente per ragioni di vicinanza linguistica se si va su temi
relativi ad Italia, città italiane, letteratura italiana, si trova molto più approfondimento... o anche letteratura latina per dire, molto più approfondimento su Wikipedia in italiano che su Wikipedia in inglese.
Come si risolve questo problema... e poi ci sono anche delle politiche editoriali differenti su Wikipedia in italiano perché Wikipedia in italiano spesso su molti argomenti è molto più selettiva rispetto a Wikipedia in inglese per discussioni che
si sono venute a creare diciamo all'interno della comunità pacificamente, alcuni temi alcuni articoli vengono cancellati molto più facilmente che su Wikipedia in inglese, specie le biografie magari di persone si tende a essere un po più conservativi.
Come si "risolve", tra virgolette?
Da un lato c'è la traduzione, ci sono molti strumenti che poi Wikimedia ha creato nel tempo per facilitare la traduzione cross-wiki, uno strumento di traduzione semplificato, modelli di supporto per la traduzione.
E questo già è un modo per importare un po' di contenuti dall'inglese all'italiano, specie su temi che non hanno questa differente impronta o approccio culturale che potrebbero avere temi un po' più vicini anche alla nostra sensibilità e che magari sono già abbastanza sviluppati.
Adesso inoltre c'è un progetto interessante che si chiama "Abstract Wikipedia", cioè la Wikimedia Foundation sta provando a creare una Wikipedia astratta basandosi su un progetto che abbiamo già creato che si chiama "Wikifunctions", che crea delle
funzioni computabili immediatamente dall'interfaccia di Wikipedia, per esempio calcolo dell'area del quadrato, c'è la funzione, metti il lato e ti esce l'area del quadrato, presto su Wikipedia sarà possibile avere un minimo di interazione del genere, oppure calcolo del BMI o altri strumenti del genere.
Quindi queste Wikifunctions in qualche modo sfruttando questo progetto vogliono creare una Wikipedia astratta, cioè sarà possibile utilizzando anche quelli che sono i semi di Wikidata, cioè su Wikidata ci sono informazioni linguistiche, oltre agli
item che dicevo prima sugli oggetti che ci circondano e quant'altro, ci sono informazioni di carattere linguistico, quindi verbi, coniugazioni, declinazioni di genere, il numero delle parole e quant'altro per ogni lingua, significati legati agli oggetti.
E quindi vogliono creare questa Wikipedia astratta in modo che sia possibile scrivere in astratto la voce una volta e poi averla riprodotta in tutta una serie di lingue.
Ora, personalmente non sono sicuro al 100% che sia fattibile come impresa, però lo stanno portando avanti e magari sarà un modo interessante di colmare un po' il gap linguistico che c'è, non tanto, non solo, tra Wikipedia in italiano e Wikipedia
in inglese, dove comunque Wikipedia in italiano magari ha fatto delle scelte su alcune voci, non ce le ha per scelta, magari altre ce le ha più approfondite, meno approfondite, però comunque... ma soprattutto tra Wikipedia in inglese è tutto un
panorama di lingue che magari hanno meno parlanti quindi anche lingue... il focus per esempio di Wikimedia era a un certo punto anche tutta una serie di lingue africane minori, che sono minori sì... o lingue indiane, che sono minori sì sulla carta
ma hanno comunque milioni di persone che le parlano e avrebbero diritto a un accesso chiaramente anche alle informazioni nelle loro lingue.
Poi è chiaro che ci sono tutta una serie di gap contenutistici più o meno ampi, penso per esempio a un tema che ritorna spesso, gender gap e quant'altro, però lì la soluzione è solo una, che ci sia qualcuno che si appassiona del tema e ci aiuta un po' a riempire i vuoti.
Questo Abstract Wikipedia potrebbe essere una soluzione interessante, così come un giorno potrebbe essere una soluzione interessante sfruttare Wikidata per "materializzare" diciamo una serie di informazioni negli articoli.
Perfetto, molto interessante questo aspetto e effettivamente rende chiaro che in realtà non è semplicemente una questione di traduzione, ma appunto c'è tutto questo tema legato alle sfumature delle lingue.
Secondo me è anche bello dare la possibilità anche a una persona che ha una prospettiva diversa dalla nostra di poter però approfondire e capire queste sfumature.
Citando appunto il caso del progetto Wikidata, quindi avere una fonte di dati strutturati e navigabili, è un tema che abbiamo approfondito anche noi tante volte ed è molto interessante perché è uno strumento fondamentale, che può essere
utilizzato appunto da un computer, da un sistema di intelligenza artificiale per ottenere informazioni corrette ed evitare quindi allucinazioni.
Anche in questo caso le nuove tecnologie potranno permettere di alimentare in modo automatico, o quasi, Wikidata anche utilizzando dei testi che sono presenti su Wikipedia, quindi delle pagine di Wikipedia?
E farlo in modo da aggiornare i dati presenti su Wikidata più di quello che è già ora?
La verità è che questa è una cosa che da quando è nato Wikidata già facciamo.
Ovviamente con metodi tradizionali, utilizzando sia i dati che erano già presenti negli infobox di Wikipedia quindi molti di quelli... anzi la totalità di quelli sono stati importati su Wikidata nei relativi item di Wikidata, sia utilizzando tutta una serie di data set esterni che sono disponibili che abbiamo poi nel tempo importato e inglobato.
La verità è che il problema è più forse non voglio dire politico, però di politica d'accesso di chi produce i contenuti, nel senso che Wikidata ha una licenza "CC0" che quindi è una licenza affine al pubblico dominio.
Significa che tutti i dati presenti su Wikidata possono essere utilizzati da chiunque senza attribuzione.
Questa licenza che è la più permissiva di tutte è incompatibile anche solo con la licenza Creative Commons Attribuzione, la più permissiva perché non è garantita l'attribuzione ai dati.
E questo... o meglio attribuzione Share Alike.
E questo è un problema perché chiaramente non possiamo importare tutta una serie di dataset anche distribuiti in CC BY-SA perché appunto non possiamo garantire l'utilizzo della stessa licenza.
Per non parlare poi di tutti quei dataset che sono rilasciati, e quando parlo di dataset penso primariamente ai dataset degli enti pubblici e della pubblica amministrazione che contengono un patrimonio di dati che magari sarebbe molto utile
importare, tutta una serie di dati sono più rilasciati con licenze ancora più restrittive se non proprio con nessuna licenza, che significa che non sono utilizzabili perché sono sotto copyright che ci impediscono appunto di importarli su Wikidata.
Poi come dici potrebbe essere interessante anche a un certo punto esplorare delle forme di estrazione un po' più legate a testi che possono essere presenti su Wikipedia o possono essere presenti in rete, fare un po' di "data mining" per Wikidata,
però essendo Wikidata un formato molto strutturato sicuramente i dati che sono già in forma molto strutturata ci aiutano molto e in realtà ci sono tantissimi dataset strutturati già presenti su qualsiasi cosa specie rilasciati alle
amministrazioni pubbliche, non sempre però con una licenza compatibile con Wikidata che ci consenta poi di utilizzarli e importarli.
Interessante poi anche l'aspetto del legame tra Wikidata ed AI, perché è un tema sicuramente di ricerca, quello di come integrare i LLM con i Knowledge Graph tradizionali, ed è una cosa che sta esplorando anche la Wikimedia... in particolare
Wikimedia Germania, a dire la verità, con un progetto che hanno chiamato Wikidata Embedding Project, in cui stanno cercando di integrare i dati presenti sono i dati con i modelli di intelligenza artificiale generativa, con gli LLM.
E quindi realizzando un'integrazione non solo di accesso, ma proprio a basso livello, cioè proprio già un'integrazione nell'addestramento, in modo che questi sistemi quando rispondono si basino sui dati di Wikidata.
È un progetto ancora di ricerca e di sviluppo di Wikimedia Germania in corso, però è un progetto molto interessante, perché andrebbe sicuramente a mitigare molto il problema delle informazioni errate, perché si baserebbero su dati oggettivi presenti all'interno di Wikidata.
Chiaramente questo implicherebbe ancora di più la necessità di rendere Wikidata più completo, ergo una maggiore attenzione da parte di chi possiede dei dati, che sia in istituzioni culturali, enti pubblici, ma anche enti privati magari, che vogliono contribuire, e li rilasciano però con una licenza compatibile.
Praticamente il pubblico dominio.
Va bene, allora grazie Ferdinando perché è stata una bella occasione per capire come funziona Wikipedia, ma anche per sottolineare tutti quelli che sono gli altri tanti progetti che realizzate e quello che è il vostro contributo nel mondo della
conoscenza sul web online, ecco, in tanti settori che non si limitano solo appunto alle pagine di Wikipedia.
E poi interessante ovviamente anche tutto il focus che abbiamo fatto sull'intelligenza artificiale da cui è emerso gli aspetti negativi, le problematicità che dovete affrontare per rendere e rimanere rilevanti, però dall'altra parte anche quello che può essere l'aiuto che l'intelligenza artificiale può dare a una realtà come la vostra.
Quindi grazie e alla prossima.
Grazie mille, grazie a te, è stato veramente un piacere.
Alla prossima.
E così si conclude questa puntata di INSiDER - Dentro la Tecnologia, io ringrazio come sempre la redazione e in special modo Matteo Gallo e Luca Martinelli che ogni sabato mattina ci permettono di pubblicare un nuovo episodio.
Per qualsiasi tipo di domanda o suggerimento scriveteci a redazione@dentrolatecnologia.it, seguiteci su Instagram a @dentrolatecnologia dove durante la settimana pubblichiamo notizie e approfondimenti.
In qualsiasi caso nella descrizione della puntata troverete tutti i nostri social.
Se trovate interessante il podcast condividetelo che per noi è un ottimo modo per crescere e non dimenticate di farci pubblicità.
Noi ci sentiamo la settimana prossima.





